谷歌AI为达目的,把自己的身体改造成了这样……

文/强化栗
来源:量子位(QbitAI)
强化学习AI打游戏,早就不稀奇了。
智能体在虚拟世界里死去活来,慢慢了解怎样的策略能让自己活得更长,得到更多的奖励。
但AI可能不知道,游戏打不好,也可能是智能体的身体结构有问题。
如果可以一边学策略,一边改身材,或许能成就更伟大的强化学习AI。
于是,来自谷歌大脑的David Ha,为自家AI制定了双管齐下的特殊训练计划:
智能体不断调整自己的身材,比如腿的长度,找到最适合当前任务的结构;同时进行策略训练。
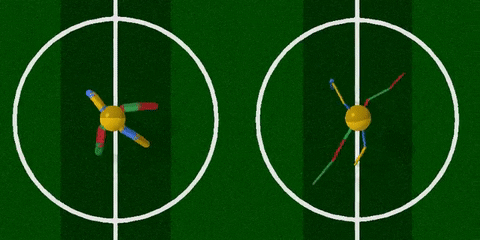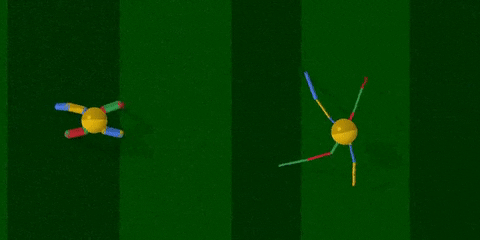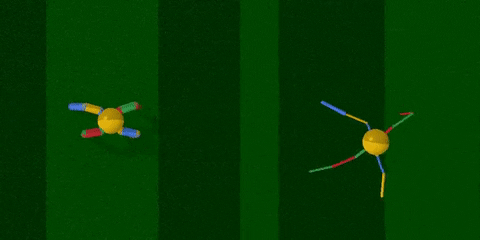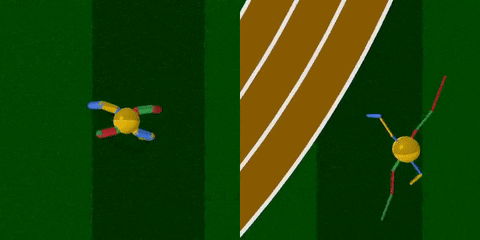
你看,智能体把腿跑细了,速度也快了许多。
除此之外,还可以培养越野能力。
在沟壑纵横的旅途中,原始身材的智能体时常翻车。

但炼成优雅身型之后,翻车事件几乎不存在了,策略训练时间也缩减到原来的30%。
身材科学了,策略也就好学了。
那么,是怎样的婀娜身段,能在降低时间成本的同时提升性能?再看一会儿你就知道了。
秀外慧中,有何密方?
从前的智能体,形状结构大都是固定的,只关注策略训练。可是,系统预先设定的身材,通常都不是 (针对特定任务) 最理想的结构。
因此,如同上文所说,策略要学,身材优化也要一起学。

这样一来,只用策略网络的权重参数 (Weight Parameters) 来训练就不够了,环境也要参数化。
身体结构特征,比如大腿或小腿的长度、宽度、质量、朝向等等,都是这环境的组成部分。
这里的权重参数w,把策略网络参数和环境参数向量结合起来,便可以同时培养身材和技巧。
随着权重w的不断更新,智能体会越来越强。

身材改造有没有用?只要和仅学策略、不改结构的智能体比一场,如果奖励分有提升,就表示AI找到了更适合这个环境的身型。
注意,为了修炼AI的冒险精神,研究人员把高难度动作的奖励扩大,引导智能体挑战自我。
身材改造,疗效甚好
比赛场地分两大块,一是基于Bullet物理引擎的机器人模拟库Roboschool,二是基于Box2D物理引擎的OpenAI Gym。
两类环境都经过了参数化,AI可以学着调整里面的参数。
解锁高分姿势
首先,来到足球场 (RoboschoolAnt-v1) ,这里的智能体Ant是只四脚怪,每条腿分三截,由两个关节控制。腿是留给AI调节的,球状身躯是不可调节的。
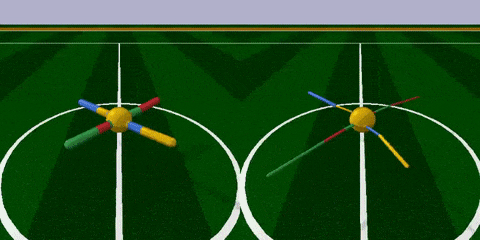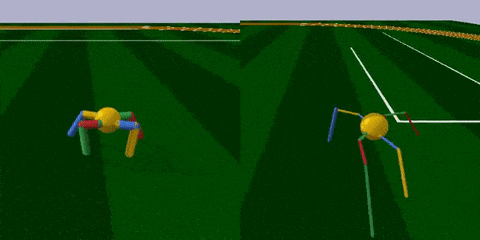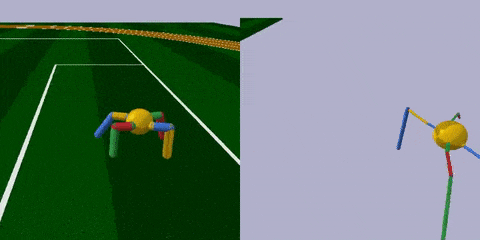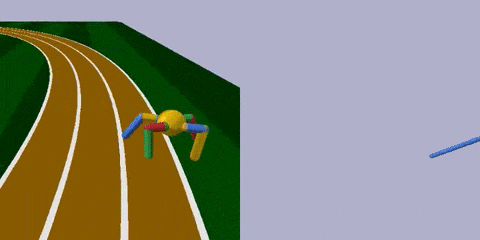
任务很简单,跑得越远越好。
经过训练 (上图右) ,智能体最明显的变化是腿部更加细长了,且四条腿长短不一,打破了对称性。身材改变之后,步频也加快了许多,长腿怪更早穿过了棕色跑道。
看一下奖励分:在100次测试里,原始结构的得分是3447 ± 251,而新结构的得分为5789 ± 479,疗效显著。

然后,进入绿地场景 (BipedalWalker-v2,基于Box2D,属于Gym) 。这里的智能体是两足的,在“激光雷达”的指引下往前走。
任务是在规定时间内,穿越一片和平的地形 (这是简单版,充满障碍物的复杂版见下文) 。用分数来看,100次Rollout超过300分就算任务成功。
原始身材获得了347分,优化后的身材则有359分。
两边任务都成功了,但改造过结构的智能体除了瘦腿之外,两腿四截的长度都有变化,给了AI弹跳前进的新姿势。动作看上去更加轻松,分数也高过从前。
好身材,能加速策略学习
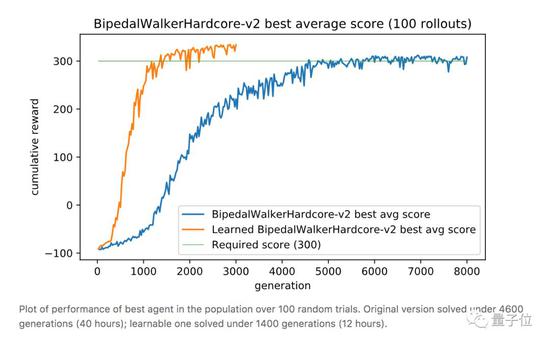
上文绿地的硬核版 (BipedalWalkerHardcore-v2) 在此:路途崎岖,千山万壑,一不小心就会堕入深渊。
David Ha要在此证明,强健的身材能为智能体的策略学习带来加成,而不只是“两门功课同步学”那样粗暴的合体。
与之前的全面瘦腿不同,这次智能体的后腿,进化出了厚实的小腿,且长度和沟壑的宽度相近。
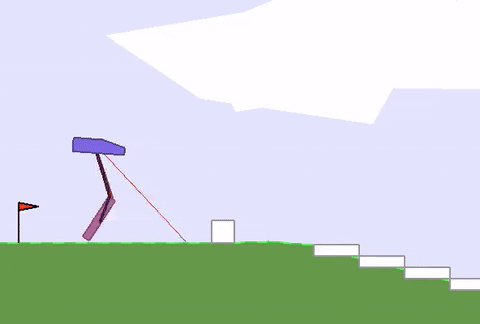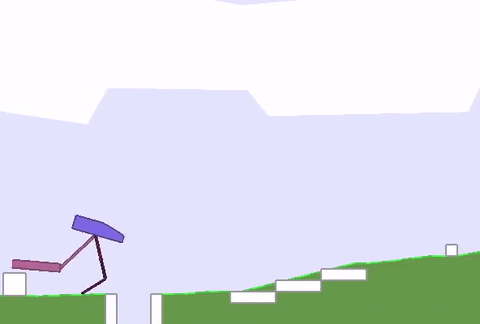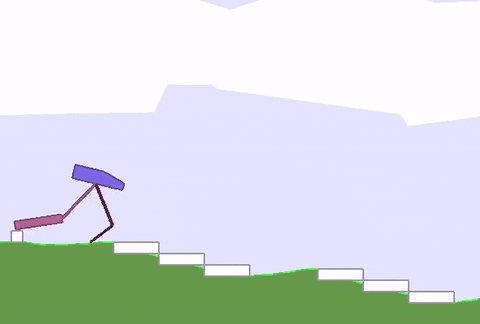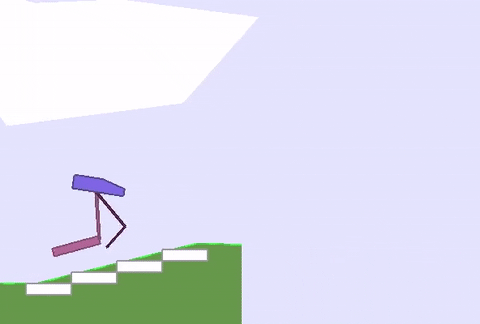
这样一来,在跨越鸿沟的时候,后腿就能架起一座桥,保护智能体平稳通过,不翻车。
与此同时,前腿承担了“危险探测器”的责任,侦查前方有怎样的障碍物,作为“激光雷达”的辅助,可以给后腿的下一步动作提供依据。
重点是,在这副新身材诞生的过程中,AI已学会了通关策略,耗时仅12小时。对比一下,不做身材优化的原始训练方法,用时长达40小时 (前馈策略网络,96个GPU) 。
这就是说,优雅的结构加速了智能体的学习过程。
脑洞,并非从天而降
第一,David Ha如何能预感到,改善智能体的结构就可以提升训练效率?
他说,是从大自然得到了启发。

有些动物在脑死亡之后,依然可以蹦跳,依然可以游泳。
也就是说,生物体的许多行为,并不依赖大脑。
有种叫做体验认知 (Embodied Cognition) 的理论认为,认知的许多特征,都不是大脑独自决定:生物体的方方面面,如运动系统、感知系统、生物体与环境的相互作用等等,都会对认知产生影响。
比如,运动员在长期训练的过程中,除了身体得到锻炼,某些特定的心理素质也会随之生成。
David Ha觉得,这样的现象在AI身上也有可能发生:对躯体进行训练,从而影响认知。
第二,通过训练来改变智能体结构的想法,也是来源于自然。

火烈鸟本不是红色,吃了小鱼小虾之类的食物,羽毛才变红
中学生物告诉我们,表现型是基因型与环境共同作用的结果。
那么,各式各样的虚拟场景,也会让更适应环境的智能体结构脱颖而出。这样,AI便可以借助环境的选择,炼成更加精湛的技能。
缘,妙不可言。

超达科技公众号

超达商城小程序
咨询热线:15890197308技术售后:15890197308邮箱:80410245@qq.com
郑州超达科技有限公司Copyright © 2017~2020 All rights reserved.豫ICP备17044048号
网站建设,网站制作,软件开发,APP开发,小程序开发首选郑州超达科技,公司拥有超达建站全网营销系统,是专业的网站建设、网站制作、软件开发公司,超达建站包含PC网站、手机网站、微信网站,小程序,手机app,一键生成,各种终端全覆盖,操作简单,任意布局,无需代码,自由拖拽! 超达科技是一家致力于为政府、企事业单位提供互联网服务的创新型企业,集软件定制开发、网站建设、网站优化、网站营销、网站运维、手机APP开发、微网站制作、系统集成、互联网应用服务为一体,为企事业单位提供全方位、多平台一站式服务。

